论文
2024
- Vision
 DimSum50: A Benchmark Dataset of Chinese FoodKunyi YuIn Applied and Computational Engineering, 2024
DimSum50: A Benchmark Dataset of Chinese FoodKunyi YuIn Applied and Computational Engineering, 2024This paper provides an overview of the increasing attention given by the public and government to food health. It also reviews the progress made in the field of image classification over the past decade, with a specific focus on the current state of Chinese food datasets. The DimSum50 dataset is introduced as the first dataset that concentrates on diverse Chinese dim sum among all publicly available datasets. This dataset comprises 50 categories of the most popular dim sum foods, containing a total of 28,884 images. To ensure the accuracy and scalability of DimSum50, a three-step construction process was implemented, including category selection, data collection, and data cleaning. The unique properties of dim sum present challenges in constructing this dataset, as several categories exhibit similar characteristics. Benchmark experiments were conducted on the DimSum50 dataset, offering a horizontal comparison among several common and state-of-the-art models in both CNNs and transformers.
- RL
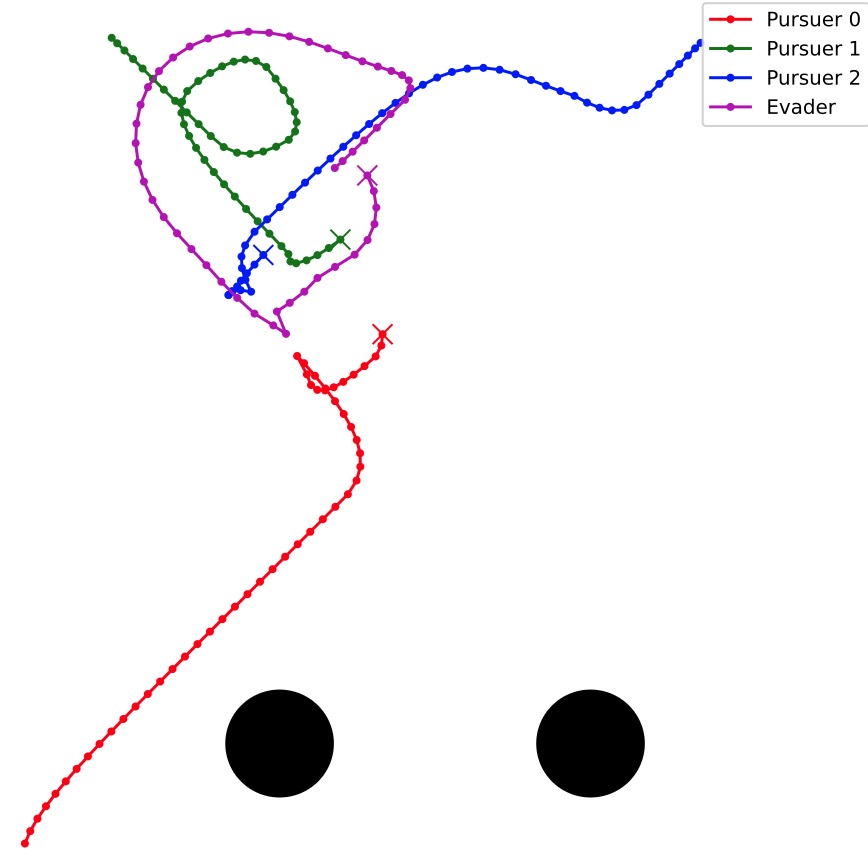 Multi-agent Cooperative Pursuit Strategy based on Reinforcement LearningKunyi Yu2024
Multi-agent Cooperative Pursuit Strategy based on Reinforcement LearningKunyi Yu2024The group cooperative pursuit problem is a classic issue in multi-agent systems with broad logistics, search and rescue applications, and UAV flight control. Multi-agent reinforcement learning algorithms emphasize learning through interaction with the environment and show significant potential for addressing this problem. Recent studies have enhanced the MADDPG algorithm with RNNs to improve performance in simple environments, yet the impact of environmental difficulty and RNN types on algorithm performance remains unexplored. This paper investigates these aspects by implementing a pursuit-evasion scenario with detailed evaluation criteria, observation spaces, action spaces, reward functions, and evader’s algorithms. Experiments reveal that limiting the observation area and increasing the evader policy’s difficulty degrade algorithm performance and reward convergence. The research improved the MADDPG algorithm using LSTM and GRU RNNs to address this. The improved MADDPG maintained performance similar to the original under partial observability and hard difficulty conditions and demonstrated strong robustness even with multiple node failures.
